

Renaldi Gondosubroto is the Founder of GReS Studio and a Developer Advocate in the tech community. Through his passion for developing software and contributing to the open-source community, Renaldi wants to encourage the innovation of new solutions to usher forward and promote a new era of innovations that can be used by everyone. He has been a tech speaker in numerous events for the past four years and runs tech meetups and workshops to promote a better understanding of technical skills.
Building on System Resilience with Chaos Engineering for Serverless Applications on AWS
About the speaker
Renaldi Gondosubroto
Founder & Project Leader,
Gres Studio
About the talk
With Work From Home being widespread due to the Covid-19 pandemic, Cloud Engineering has become more needed than ever due to the shift of applications to the cloud. This talk will discuss how teams plan for and execute chaos engineering to ensure resiliency and availability in serverless projects.
With Work From Home (WFH) becoming widespread as a working practice worldwide due to the Covid-19 pandemic, preparing for unexpected conditions has become more important than ever. More and more businesses have transitioned to seeking better resiliency and availability by transitioning towards and deploying serverless applications on cloud platforms such as AWS. This trend will most likely continue to grow, even after the end of the pandemic, as more start to have their on-premises equipment dependent on the cloud.
This talk will discuss how teams can plan for chaos engineering within serverless projects on AWS, and the necessary measures to put in place to improve the system in terms of availability and resiliency. This will include best practices in coding for chaos engineering on serverless applications, considerations to keep in mind when planning chaos engineering for a new serverless project, understanding how to apply chaos to different components of your serverless application infrastructure while fixing things as they break, how to work with error and latency injection on your serverless application and setting up a disaster recovery plan to apply chaos to and develop. Alongside this, I will also give a case study of one of my own projects as well to allow attendees to better visualize how these are all applied within a use case's context.
Transcript
Building on System Resilience with Chaos Engineering on AWS
For yet another insightful session on day 2 of Chaos Carnival 2021, we had with us Renaldi Gondosubroto, Founder and Developer Advocate from GReS Studio, to speak about "Building on System Resilience with Chaos Engineering on AWS".
CHAOS ON THE CLOUD
The way we work is changing due to COVID-19, including the bigger transition towards serverless and cloud applications. We have been going through more shifts towards this kind of culture, and we need to be able to make our testing more resilient, be prepared for faults and misconfigurations.
The three main principles of cloud:
Firstly, Resiliency towards failures, potential threats, or other disruptions. Secondly, availability tells us how ready our system is for any type of downtime or outages. Thirdly, adaptability is a way to see if the system can accept the changes in workload on the production.
THE ENDEAVORS
The first endeavor essentially is to define and attain stability. As we plan for Chaos Engineering, we need to decide what is stable on the cloud. We need to consider it as a normal behavior because we need to define the steady-state. Align this normal behavior to your business objectives. It is important because it lets us know if our current objectives are correct or not. The second endeavor is the estimation process. It is used to estimate how we will be applying it on the cloud and where chaos is being injected. The third endeavor is execution. It helps you to create a flow diagram on how you plan to execute an experiment step-wise. Prepare containment methods of your experiment, you do not want it to affect a large part of the system in the initial stages itself. The fourth endeavor is to evaluate. It helps to define metrics that define our measure of success. And with these factors, we will be able to measure resilience and how robust our system is. Continuous evaluation helps in learning and understanding your system for better experiments. The fifth and the last endeavor is reiterations of processes like experimentation and improving the steps involved. We can understand the effects by analyzing the findings of previous experiments.
WHAT TO WATCH OUT FOR
-
Handling various responses: In AWS, there are a lot of things to worry about. Starting from a timeout for each service so that we can adapt other services testing.
-
Creating chaos at an acceptable level: Based on the overall system, we choose to create chaos to an acceptable level, defining this level beforehand.
-
Failover plans: One of the AWS pillars is that every developer prepares for availability and failover because regardless of how infrastructure might seem, it stands a fair chance to go down.
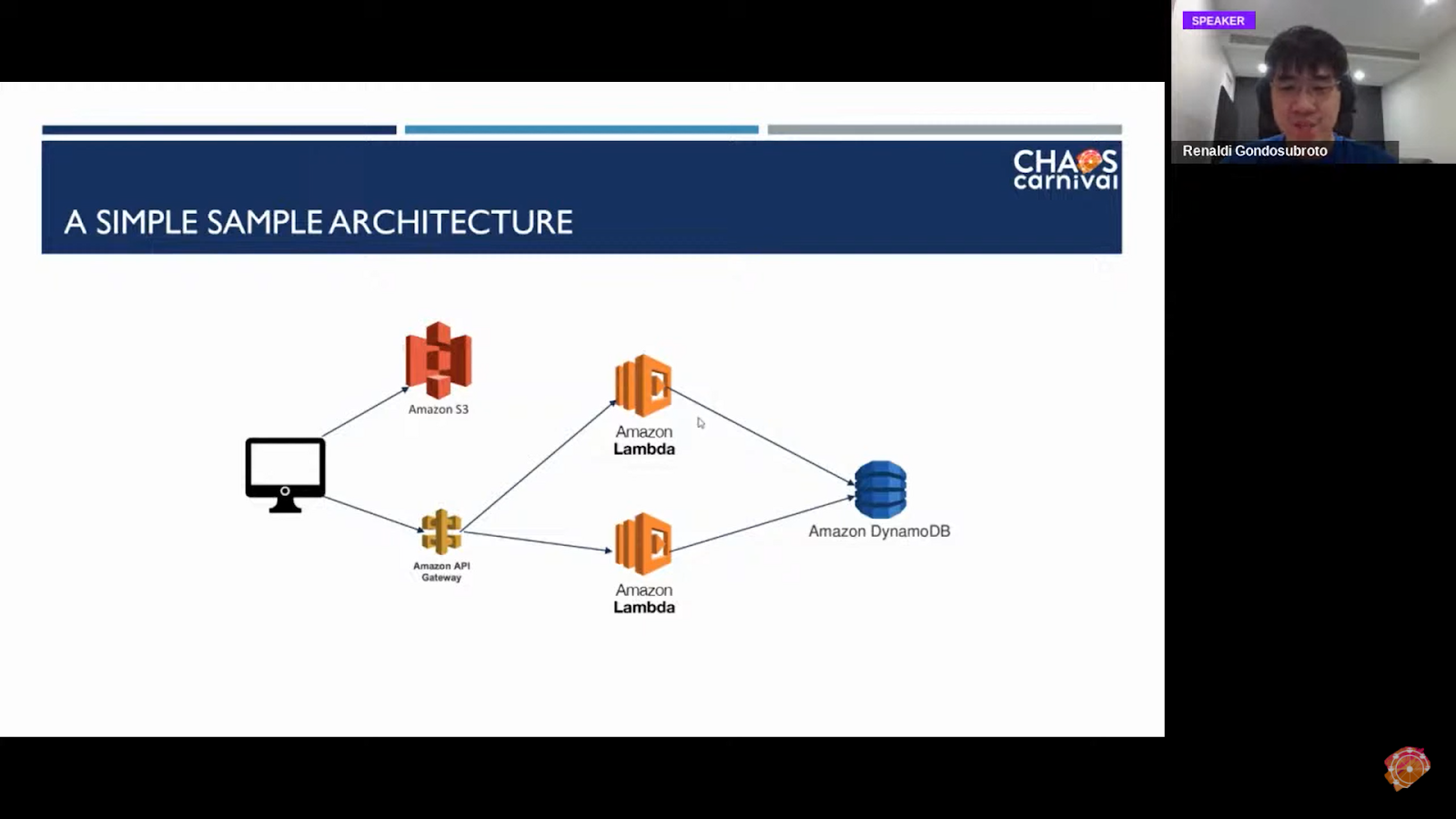
For example, we have a particular architecture that connects this way. We use DynamoDB as our particular database and Lambda is used as an API gateway that acts as a border between our code at Lambda. S3 is another code source apart from the previously mentioned.
CREATING YOUR OWN PLAYGROUND TO EXPERIMENT
-
Create a test account: This will help one create a production environment first which is geared towards testing.
-
Experiment with varying parameters: This can be done using the test accounts on a similar architecture mentioned above.
LATENCY INJECTION IN AWS COUNT
Latency spikes and performance issues are something you should be considering early. These issues are essentially the most common in production environments. These issues may include network unreliability, overloaded servers, etc. API gateways have a hard limit of 29 seconds for the timeout. These issues need to be configured while simultaneously running other services.
In this particular scenario, we want to be able to create an HTTP client and we can inject it within the HTTP client library. In addition to that, we will be injecting chaos within the AWS SDK itself which will run the process of data sending to the DynamoDB. This helps us obtain requests and ensure the degrees are successful. Simultaneously, we will be able to test for the function's timeout as well. It can degrade accordingly in the request's timeout. We need to work with other services which are being used and accordingly adapt in complex environments.
Renaldi then goes on to explain how chaos can be applied in DynamoDB, Lambda, and anywhere in AWS.


CREATING A POST-INCIDENT STRATEGY
Creating a positive strategy after the completion of the experiment is very crucial. We need to answer multiple questions like what exactly happened, how did this affect your service, how can you control the chaos better the next time, what are those metrics that need to be reevaluated, what are we doing at the moment to fix this, etc. for efficient documentation, which will make our upcoming experiments more successful. Creating a weekly inspection schedule for the monitoring of Chaos Engineering flow, focussing on components and getting them prepared for the next experiments, and discussions on the agile-scrum culture are other ways for strategy planning.
CASE STUDY
Renaldi goes on to describe a case study wherein he needed to build a resilient system for an IoT network while considering client constraints of low bandwidth in the areas. He then explains how to best utilize the cloud platform to facilitate it. He used Lambda for the selection of testing and putting high pressure on bandwidth in locations. Testings were scheduled accordingly.
NEED OF AGILE IN CHAOS ENGINEERING
Agile is all about interactive development with the teams. You need to share the findings and the documentation after each experiment so that everyone is aware of what they are contributing towards. Chaos Engineering needs fast reactions, hence onboarding the team beforehand will be beneficial as they will be ready. Developers need to prioritize disaster recovery and failover for handling any unknown situation with ease.
Towards the end of his talk, Renaldi mentions, "We got agility, satisfaction, and culture-building through conducting chaos experiments and it is highly recommendable to anyone who is looking for building a resilient system."


Videos
by Experts
Checkout our videos from the latest conferences and events

