

Michael Knyazev, PhD. in DevOps Engineer, Customer & Location Services at Insurance Australia Group. Michael has helped design, build and operate world-class solutions like National Coronavirus Helpline (Big Data, Integration, AWS), Morningstar's Tick Data HA / DR Platform (Big Data, AWS), Beam Wallet (FinTech, AWS).
Building Reliability Pipelines with Chaos Workflows
About the speaker
Michael Knyazev
DevOps Consultant,
iag
About the talk
This talk describes how Chaos Engineering techniques were used at Insurance Australia Group to ensure better systems reliability. It goes into architectural details of Reliability Pipeline, such as: the Kubernetes resources organization, Litmus components orchestration, leveraging Argo Workflows.
Transcript
Building Reliability Pipelines with Chaos Workflows
For an enlightening session on day 2 of Chaos Carnival 2021, we had with us Michael Knyzev, a DevOps Consultant from Insurance Australia Group, to speak about "Building Reliability Pipelines with Chaos Workflows".
Michael starts off his talk by saying, "Motivation is a key aspect of implementing chaos experiments. We need to regularly verify that our platform is reliable. The system is resilient to work node failures but might be lacking the resources. It is able to cope with significant user requests as well. However, speaking of some cons of chaos testing are that it is time-consuming, the whole platform can get unhealthy, and it requires special set-up and clean-up at platform scale."
Through chaos testing, we can correct the system components' stabilization via resources tuning and app start-up times as well as health-check optimizations. It also verifies the error response percentage satisfaction under stress load and cluster auto-scaler scaling in and out of EKS as expected. Pipelines run on a temporary EC2 node in the EKS cluster and are built using LitmusChaos and Argo workflows. These are the chaos tests that are run in CI/CD pipelines:
-
Kill app replicas 50-100% and measure the success/error ratio.
-
Provision stress number of app replicas and check platform scales.
"When we were opting for tools, we were closely looking at a few CNCF projects like Chaos mesh and LitmusChaos. When we suggested a few customized improvements to them, they very willingly accepted it and we chose Litmus as our prime Chaos Injector.
As you can see, we have a Chaos Hub, which contains the definition and details of the experiments. We then add the definition and details of the applications such as pod to Chaos Engine which then tries to map them. Once the mapping is done successfully, the application is passed down to the Chaos Operator. The Chaos Operator is responsible for managing the experiments and Kubernetes deployment using the Operator SDK. We can use such experiments using YAML and are implemented by the community. From there on it goes to Chaos Runner which injects a specific chaos experiment and then we wait for the result. You can check the Chaos result with your hypothesis at the start of the testing if it is valid or not.

Michael then goes on to explain the Argo workflows in two separate ways: JAVA and YAML.
Each of the methods can run on it's separate containers. Those containers are called pods and are orchestrated by Argo Engine. The Argo UI is feasible for customers with rich logic modelling syntax to run Kubernetes and easy to orchestrate docker containers as workflow steps.
EXAMPLES OF PIPELINE CODE:
"The three pipeline codes which you will see here have their building blocks as Argo Templates." explains Michael.
- name: curl-jq
Here, the images are contained in curl-jq using the commands bin/sh. It executes the command line and the parameters.

- name: run-benchmark
It is defined in YAML and the image here is inserted using a popular tool called Vegeta. It has the ability to apply stress and measure statistics of responses.

- name: chaos-pod-delete
This is the primary example of an Argo Template with LitmusChaos. Here we apply the Kubernetes definition and this definition is Chaos Engine. It acts as a component which helps in running chaos experiments by killing a fixed number of replicas for the disruption of a service.

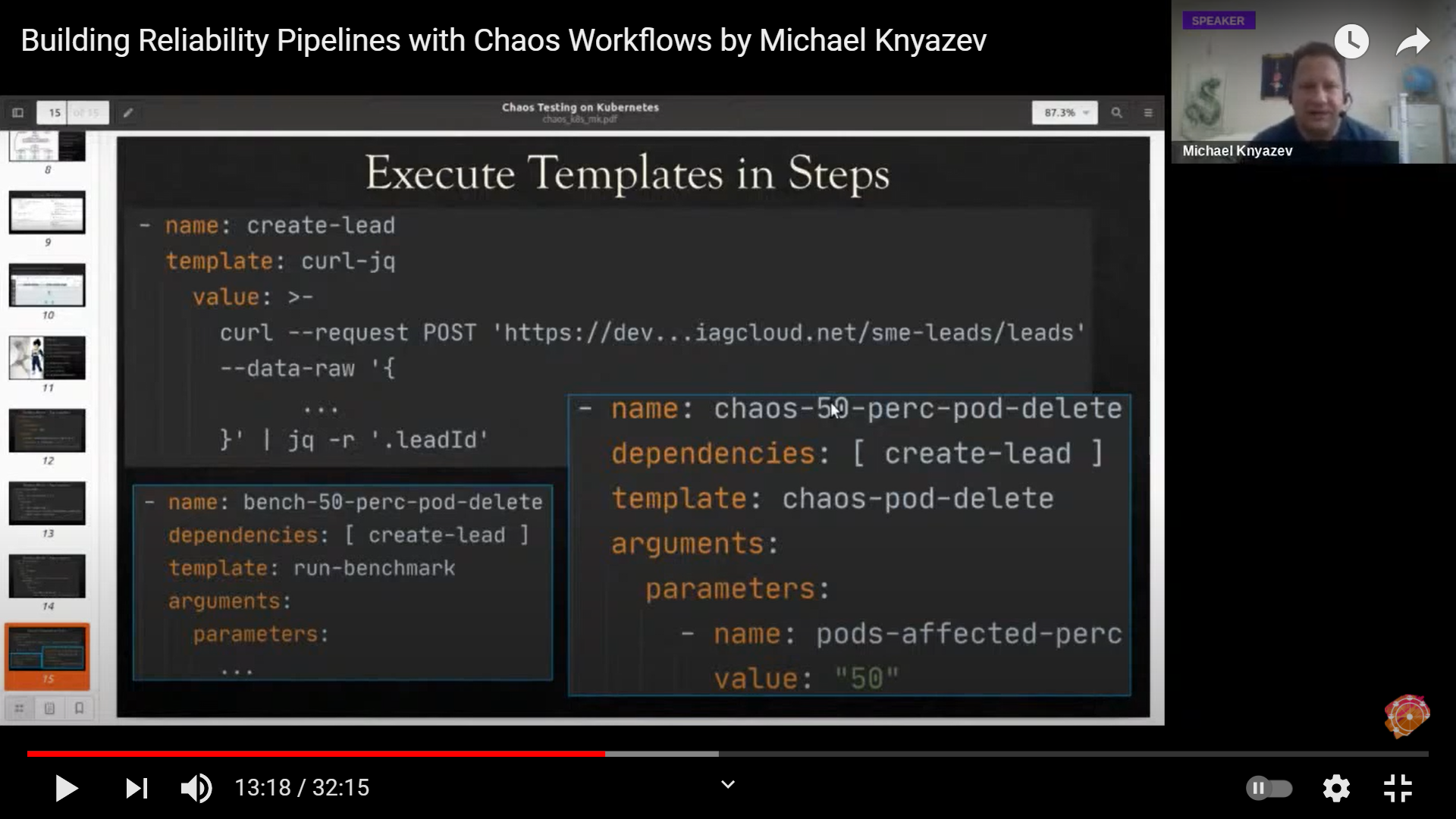
EXECUTE TEMPLATE IN STEPS
We first start off by taking the curl-jg argo template and the parameter used is the actual command of curl. Next we use chaos 50% pod delete by passing 50% of replicas we want to kill. The template used here is chaos-pod-delete defined by chaos engine with chaos experiments inside.
Michael concludes the talk by giving a detailed demonstration on how to define the EKS Cluster by Terraform and on how to create Reliability Pipelines.


Videos
by Experts
Checkout our videos from the latest conferences and events

