

Sumit Nagal is a Principal Engineer at Intuit; he is a maintainer and contributor to many open-source projects. He is an engineer on the "Productivity Group" as part of the "Core Services" group in Intuit. He is focusing on Intuit Kubernetes Platform reliability for Intuit. In his 15 years at Intuit, he worked on most of Intuit's products. He has played various roles, including Architect and Developer, and leading numerous successful initiatives and innovations to fruition.
Evolution in Chaos Engineering
About the speaker
Sumit Nagal
Principal Engineer,
Intuit
About the talk
Gone are the days when we lived on the stone edge; we have gone through the most significant evolution in humans. A similar shift is happening in chaos Engineering, wherein in the past, minimal visibility with a limited tool like chaos-monkey, Symbian army, we were building finite solutions. Today we have Chaos tool-kit, litmus-chaos, Chaos Mesh type of open source & Gremlin, ChaosIQ like a commercial solution for more extensive adoption. Thanks to massive growth in infrastructure, which made reliability as necessary attributed to the Application System Design. Today, many companies participate in GAME Day, and Chaos is a company-wide initiative. On Chaos Many Open source and commercial solutions available on various platforms.CNCF has a couple of Chaos engineering solutions on sandbox projects, which brings awareness to Chaos. Now, Application resiliency and service Stability has broadened to Technology, Platform, and Cloud. It is an evolution from Netflix chaos-monkey to AWS FIS, creating a real buzz on cloud providers. Now, chaos engineering becomes a first-class citizen on CNCF radar. Chaos' conference and awareness on social media is another dimension where chaos Carnival is part of that evolution.
Transcript
Evolution in Chaos Engineering
For an enlightening session on day 2 of Chaos Carnival 2021, we had Sumit Nagpal, a Principal Engineer from Intuit, join us to speak about "Evolution in Chaos Engineering".
Sumit kick-started his talk by saying, "In humans, we have seen evolution which took centuries. A similar shift is happening in Chaos Engineering, where we have evolved from using a minimal toolset and to now having multiple solutions. But unlike human evolution, chaos evolution is catching up swiftly."
"Evolution is defined as the process of growth and development, or the theory that organisms have grown and developed from past organisms." This is how Sumit defines evolution. Chaos Engineering is growing because the internet has been going through some rapid changes in the past decade, and will keep increasing in a similar fashion. With this, the IT world is changing its base to a cloud framework, which is fast, secure, and reliable. The way these are influencing the market and research is bound to increase the revenue expenditure and income. As these kinds of technology are altering with more benefits, they come with more complexities, hence more chances of failures and outages. This happens to microservices all around the globe and is rarely region-specific. According to Gartner, the average cost of IT downtime is $5600 per minute, which means it's $300K per hour. The impact of all this is the loss in revenue, loss of productivity, compliance cost, de-branding, and stock price.
Sumit goes on to quote Werner Vogels by saying, "Failures are a given and everything will eventually fail over time." A new study reveals that 96% of the enterprises face costly IT outages even though 51% percentage of the downtimes are avoidable. There are a vast set of reasons for such outages, some of which are, network, usage spike, human error, software malfunction, third party, and infrastructure & hardware.
Sumit defines Chaos Engineering as "Chaos Engineering is the discipline of experimenting on a system, in order to build confidence in the system's capability to withstand turbulent conditions in production."
First of all, we start with a hypothesis that what you want to achieve at the end of the experiment or what end result you see the projectile of the experiment landing. After injecting harm, for the test to be successful, the system should restore back to its normal working conditions. Even though the result does not match the hypothesis or if the test is unsuccessful, it will be a good learning experience and improvise on forthcoming experiments. The application is up and is load balanced with a node. The node is responsible for running three pods. To validate the pre-steady state, we can check the number of instances of the health of the end-point. This ensures that the system and service are ready to inject the chaos by deleting a pod or terminating a node. Post that, we check on a post-steady state with the hypothesis, if the health check is up and the number of instances is intact. If yes, then the system has passed the chaos test, lest failed. Basically, we pick the use-case, the framework solution, and the tool for experimenting. We prefer this framework on Kubernetes and we invoke that through custom resources API command line and through execution, we get the report.
The main reason why Chaos Engineering is growing is awareness in the modern IT world.
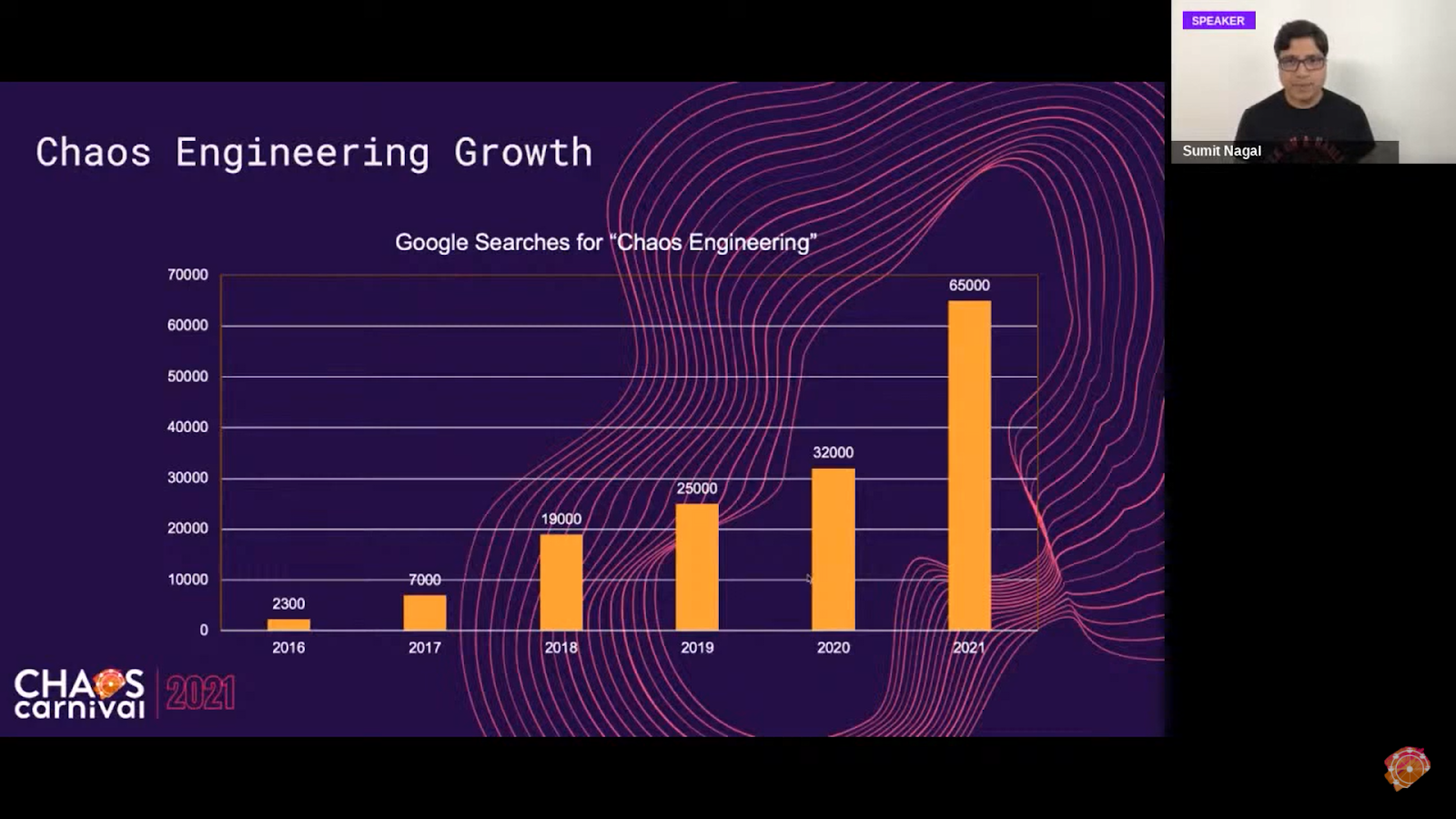
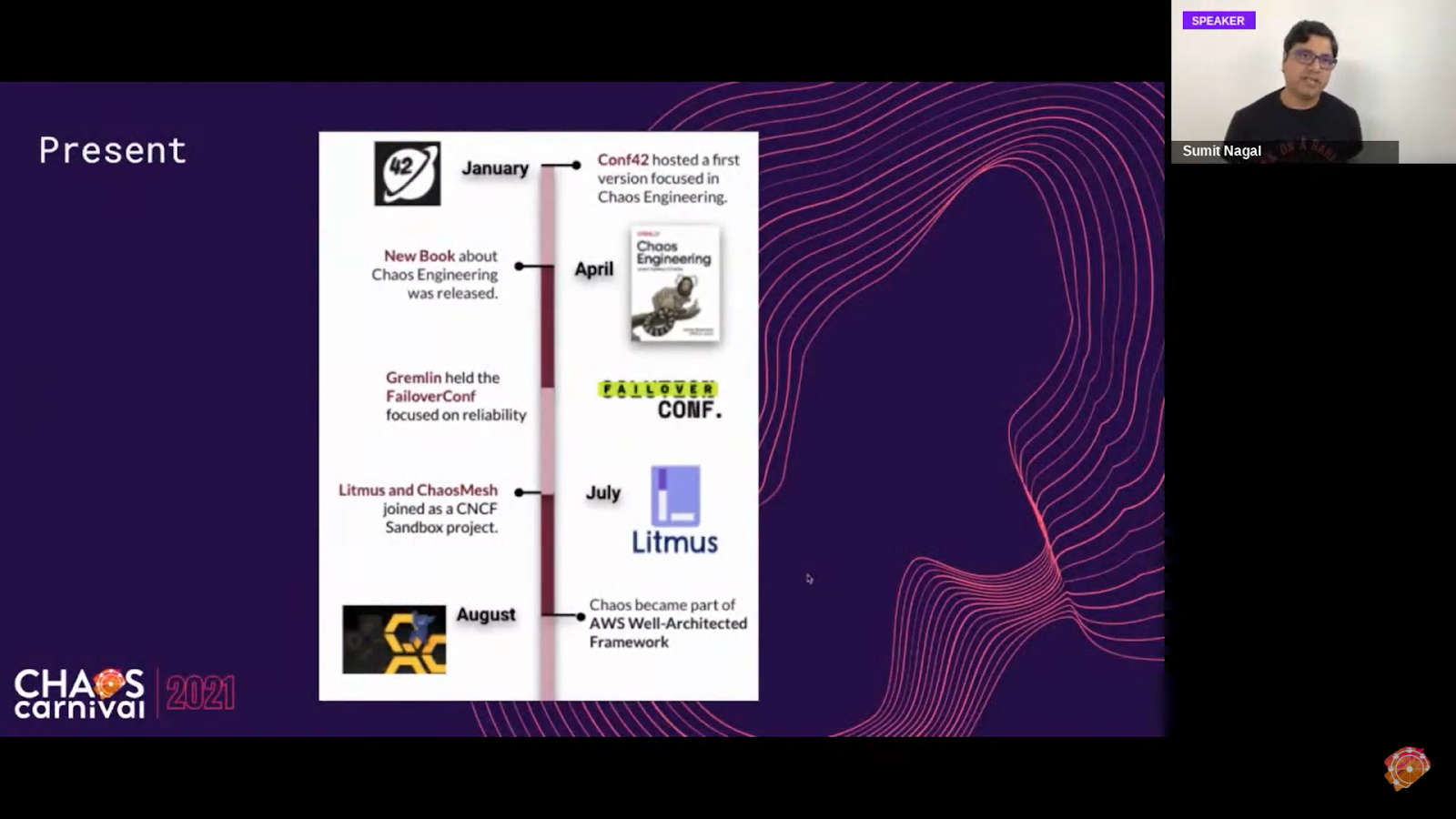
In 2004, the idea of Chaos Engineering emerged when Jesse Robbins, the master of disasters from Amazon mentioned it. In 2010, Netflix will go on to implement Chaos Monkey to enforce the use of autoscaled services. NetflixOSS then open-sourced Simian Army in 2012 and four years later, Gremlin Inc. was founded. From 2018 on, the idea and benefits of Chaos Engineering came to light and it started being widely adopted, and since then we have seen many entities providing solutions for the same like Chaos Monkey, Netflix OSS, Gremlin, Chaos Toolkit, and from the CNCF Community, we have LitmusChaos, Chaos Mesh, Steadybit, etc. with ChaosIQ and AWS-FIS.
There are various kinds of chaos available:
-
Cloud resources-based: AWS, GCP, Azure, etc.
-
Platform-based: Kubernetes, etc.
-
Cloud-Native services based: Chaos Mesh, Prometheus, Core, DNS, etc.
-
Operating system and network-based: Packet, I/O, CPU, Memory, etc.
-
Databases and storage-based: RDS, EBS, etc.
-
Support application-based: Kaka, Cassandra, etc.
Through integration as a solution, we can run our Chaos Engineering experiments with efficiency, and they have become an important part of the DevOps toolset. The different aspects in which integration can be applied are security, observability, CI/CD and Quality Gates, workflow, GitOps, and DevOps tools.
Books are a great place to educate yourself about Chaos Engineering and be a part of this rapid-changing evolution. Drift into failure, Chaos Engineering Observability, Security Chaos Engineering Oreilly's Chaos Engineering are some of Sumit's top picks. Chaos Engineering, in general, is implemented in different avatars in organizations. It might be called a gameday, chaos day, breaking this into production, reliability, preparing for outages, FMEA, people's system, etc. There has been a lot of impact on the industry through Chaos Engineering, not only in the field of resilience but also opportunities. There have been many jobs roles such as Chaos Architect or Chaos Engineer that have opened in the past few years. With 200+ GitHub repositories, 16,000+ GitHub stars, we have over 6+ conferences, 8+ communities, 5+ meetup groups, and 8+ CNCF projects dedicated solely to Chaos Engineering.
Chaos testing has a maturity level of its own. In sophistication, we start off with elementary and simple chaos experiments, and the goal should be one day to implement sophisticated experiments on complex components. In terms of adoption of the project, it starts off within shadows, as the project is still under a building and testing phase, gradually moving towards investment and adoption with cultural expectation.
Sumit thanks to the massive growth in infrastructure which made reliability in infrastructure non-negotiable. Many companies are running game days as a network-wide initiative. CNCF is already recommending more than eight tools which can get you started with chaos testing and help contribute to this evolution. Applications, resiliency, and service stability have broadened the technology platform and cloud.

Sumit ends his talk at Chaos Carnival by saying, "All in all, if I were to sum up, my talk briefly, I would say, Chaos Engineering is the next big thing in our industry with numerous opportunities which will not only benefit you and your systems but also your teams."


Videos
by Experts
Checkout our videos from the latest conferences and events

